For today’s post, I’m finally going to examine NTFS attributes. I’ve mentioned and discussed various attributes in previous posts, and asked you to just trust me in the interpretation. Today, we’ll finally get our hands dirty with these.
I’m going to start with a brief discussion of how attributes are used in NTFS and then we’ll look at the $AttrDef file, which will lead to a list of the most common attributes that you’re likely to see on an investigation.
Note: I do not cover all attributes in this post in detail. They will be mentioned as we take apart $AttrDef, but will not receive as deep a dive as others. This is not to take away from their significance, instead I focus on ones that often get the most focus during typical investigations.
NTFS Attributes
Before I start examining the various types of attributes, it’s important to know as a DFIR analyst what they really are. Many assume that when files are created, data is written to a disk and then attributes are simply the metadata maintained about the file. This is not entirely true — “files” on NTFS are actually collections of attributes, and how that data is presented to us is often how it is interpreted. Here’s a screenshot of some fairly common data:

To some, this is just a file listing in Explorer. To a DFIR analyst, this is a graphical representation of multiple NTFS attributes. As we get further through this post, it will start to make sense and you’ll find yourself looking at files through a new lens.
$AttrDef File
Before I jump into various attributes, I first want to briefly discuss the NTFS file $AttrDef. As I’m sure some can imagine, after extrapolating a name like $BadClus, this file contains a list of attributes supported on the volume and their corresponding details. This file is located at MFT entry 4. Here’s it’s istat output on a test image:

A few takeaways from this output:
- Our timestamps line up with previous NTFS artifacts, again giving us an idea of when the file system was created.
- Take a look at the bottom of the output, and we can see that this particular file has four attributes: $STANDARD_INFORMATION, $FILE_NAME, $SECURITY_DESCRIPTOR, and $DATA. This feels like a bit of an odd circular reference with NTFS that we’ll just trust for now :)
- We can easily see that the file is 2,560 bytes in length.
This file contains 16 160-byte chunks (hence the size of 2,560) that contain volume attributes and certain properties. We can break down one, and thus break down them all.
Here’s the beginning of the file in hex:

I’m going to break down the first attribute, $STANDARD_INFORMATION. Here’s it’s content up close:

- The first 128 bytes are reserved for the attribute name, stored in Unicode.
- Bytes 128–131 (
10 00 00 00) provide the attribute type ID. $STANDARD_INFORMATION’s type ID is 16. - Bytes 132–135 provide the display rule.
- Bytes 136–139 provide the collation rule.
- Bytes 140–143 (
40 00 00 00) contain flags, which determine whether the attribute is resident or not, or if it can be used in an index. In this case, our flags say that this attribute is resident. - Bytes 144–151 (
30 00 00 00 00 00 00 00) give the minimum attribute size in bytes. In this case, our attribute can be as small as 48 bytes. - Bytes 152–159 (
48 00 00 00 00 00 00 00) give the maximum attribute size. In this case, our attribute can be as large as 72 bytes.
And that’s it! This attribute is a good one to examine, because it actually has size minimums and maximums, as well as resident flags. However, consider another attribute, such as $DATA, which holds the raw data of a file. Look at it’s attribute definitions:

Data can have a minimum size of 0, and a maximum size of..well, 0xFFFFFFFFFFFFFFFF. This is equivalent of unlimited, however obviously we’ll run out of disk space first!
Just glancing through the Unicode, you can get a feel for the various attributes defined in this file. These should start to seem familiar. Let’s cheat, and use the strings command to list all of the attributes that are defined in this file:
:/mnt/windows_mount# strings -el \$AttrDef
$STANDARD_INFORMATION
$ATTRIBUTE_LIST
$FILE_NAME
$OBJECT_ID
$SECURITY_DESCRIPTOR
$VOLUME_NAME
$VOLUME_INFORMATION
$DATA
$INDEX_ROOT
$INDEX_ALLOCATION
$BITMAP
$REPARSE_POINT
$EA_INFORMATION
$LOGGED_UTILITY_STREAMHopefully, at this point in the blog series, this list looks familiar! Let’s go back to our fsstat output from this image that I posted in Part 1, when I looked at NTFS clusters:
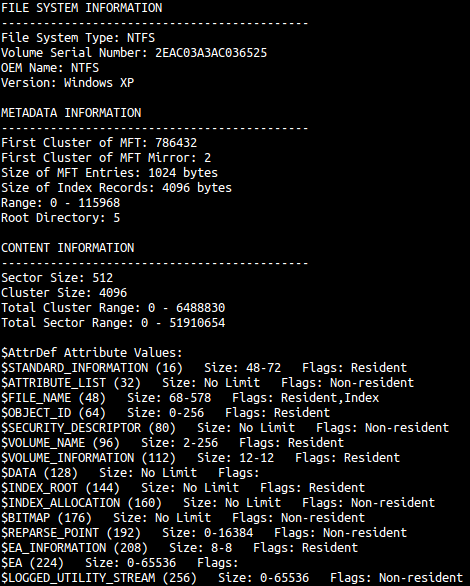
As you can see, this tool actually parses this file for us, and provides information such as either the attribute is resident, whether it can be indexed, and its range of sizes.
A Few Attributes
Now that we’ve looked at the attributes defined in the file $AttrDef, let me spend some time on a few attributes that you will commonly see in DFIR analysis. Let’s use the attributes from the file $Volume to help guide this example. Here’s the istat output again:
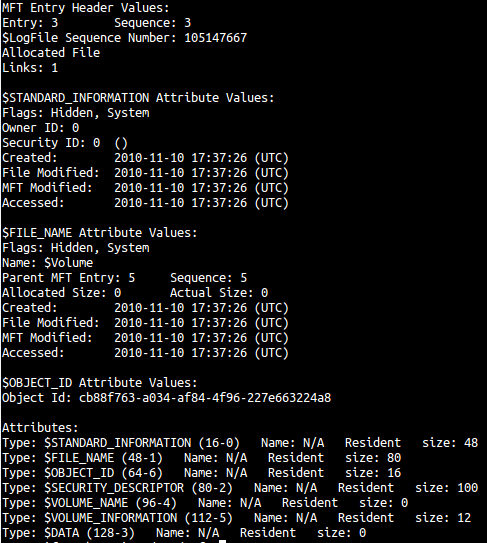
The following attributes are discussed in order of their type ID.
$STANDARD_INFORMATION
This attribute has a type ID of 16, and is the first attribute in a MFT entry. Here’s the raw data from the example file $Volume:

- The first 32 bytes are four 64-bit NTFS timestamps that contain the file Creation, Modified, MFT Modification, and Access times respectively. You can just glance at the hex and see that these are all the same; this lines up with our
istatoutput, which shows each timestamp to be 2010–11–10 17:37:26 UTC. NTFS timestamps record the number of 100-nanosecond intervals since January 1, 1601. - Bytes 32–35 contain flags that determine file properties, including if the file is read-only, a hidden or system file, compressed, or sparse, to name a few among many. In this case, a flag of
06means the file both a System file and is Hidden. - Bytes 36–39 and 40–43 provide the maximum version and version number, respectively. If these are 0 (as in this example), then they are not being used.
- Bytes 44–47 provide the file class ID.
- If you have a larger $STANDARD_INFORMATION attribute, sometimes upwards of an additional 24 bytes, this will provide information related to Disk Quotas and USN sequence numbers.
It’s important to note that a large majority of displayed or recorded timestamps are $STANDARD_INFORMATION times, including Windows Explorer and timestamped artifacts such as the AppCompatCache.
$FILE_NAME
This attribute has a type ID of 48. Here’s the raw data from the example file $Volume:

- The first 8 bytes contain parent reference information, particularly the parent sequence number and MFT entry. In this case, we have a value of 5 for each, which tells the analyst that it’s in the root directory (which has an MFT entry of 5).

- Similar to $STANDARD_INFORMATION, the next 32 bytes contain Creation, Modification, MFT Modification, and Access times, respectively. For this particular file, they match up with our $STANDARD_INFORMATION timestamps.
- Bytes 40–47 provide the allocated size of the file. As we already know, this file is 0 bytes in size, and thus has a zero.
- Bytes 48–55 provide the real size of the file.
- Bytes 56–59 contain the same flags as $STANDARD_INFORMATION, and once again confirm the file is both Hidden and a System file.
- Bytes 60–63 provide a reparse value, used by $Reparse.
- Byte 64 (
07) provides the length of the name of the file, which is 7 characters in this case. - Byte 65 (
03)provides the namespace of the file. This can range from 0 to 3. A value of 3 indicates that the file name fits within both DOS and Win32 namespaces. - Bytes 66–79 (
24 00 56 00 6f 00 6c 00 75 00 6d 00 65 00) provide the file name,$Volume, in Unicode. As you can imagine, this field can be variable in length, depending on the file name. This is why the max length of our $FILE_NAME attribute is defined at 578 in $AttrDef, and the minimum length is 2 (a filename of at least one character!)
$OBJECT_ID
This attribute has a type ID of 64. Here’s the raw data from the example file $Volume:

- This attribute is 16 bytes in length, and contains the 128-bit object ID. While not normally utilized by users, this ID can be used to access the file instead of it’s file name. These are actually utilized by LNK files, which you can create in one place and move around if need be without breaking references. However, this is dependent on the index at $Extend\$ObjID — I’ll cover this, and LNK files, in a later post.
- You may see some similarities among object IDs, as there actually is a structure here. The object ID gets converted to the following format:

The format for this object ID is <object ID>-<creation volume ID>-<creation object ID>-<creation domain ID>. Again, more on this later.
Volume-Related
We’ve already examined Volume-related attributes in the Part 2 post. I’ll briefly touch on these as they are available here:
$VOLUME_NAME
This attribute has a type ID of 96. There is no raw data from this attribute, as it has a size of 0 and the volume has no label.
$VOLUME_INFORMATION
This attribute has a type ID of 112. Here’s the raw data from the example file $Volume:

As discussed in the previous post, this gives is a volume version of NTFS 3.1.
$DATA
This attribute has a type ID of 128. There is no value for this attribute, as it has a size of 0 and the file $Volume contains all it needs to in the attributes. However, a few considerations when examining the $Data attribute:
- This attribute can be resident or non-resident. Most DFIR analysts have heard of resident files — these files are small enough that their raw data can be contained within the $DATA attribute, and thus within the MFT entry. Larger files have their $DATA attribute stored in external clusters, and thus are non-resident.
- The $DATA attribute has no size or structure; it’s meant to contain raw content, and as we see in this example, can be 0 bytes in size.
Additional Resources
Unfortunately, all of the information above can be tough to memorize. Luckily, the community has rallied and there are resources available. Jared Atkinson, the creator of Invoke-IR, has created various NTFS infographics that display the information for various NTFS attributes. You can find copies of those posters here, and I’d highly recommend keeping them on hand. Thanks Jared for an awesome collection of files!
Wrapping It All Up
Hopefully, this post has given you a new perspective on NTFS attributes, what a file really is on NTFS, and how our tools gather the data that is displayed. There are a few key takeaways from this post in general that I want every DFIR analyst to make sure they are aware of:
- If you’re unsure, don’t rely completely on what your tools tell you — you can always go to the source NTFS metadata files and examine it for the correct values.
- Files rarely have only four timestamps — despite the fact that some tools only show you four. If you have an attacker capable of timestamp manipulation, make sure to look at your other timestamps!
- Some files may have can be referenced by their Object IDs. I’ll discuss this artifact later, but know that it’s there.
- Some of these attributes contain IDs that link to other NTFS artifacts, such as the $LogFile Sequence Number. Let the interweaving of NTFS work for you, and provide additional evidence sources.
Looking Ahead
If you’re familiar with NTFS attributes, you’ll notice that we left out various INDEX attributes, which often relate to directories and metadata files. I’ll be going over these tomorrow, and Monday we’ll finally jump into the MFT. Thanks for sticking with me this far!
Until tomorrow, Happy Forensicating!
